
Beyond Basic Generation — Evaluating T2I Models in Complex Scenarios
Introducing Qwen-Image-Bench, a creator-centric text-to-image model evaluation benchmark.

Text-to-image (T2I) generation has become a core component of professional creative workflows. Yet as leading models approach saturation on standard benchmarks, a growing gap remains between benchmark scores and real-world performance.
Most existing T2I evaluations focus on semantic alignment and image quality. In practice, however, applications such as visual storytelling, branding, game art, and comics require much more. Models must demonstrate robust visual aesthetics, logical reasoning capabilities, and precise text rendering under strict constraints.
To address this gap, we introduce Qwen-Image-Bench, a creator-centric benchmark co-designed with professional artists and grounded in real-world creation scenarios. It contains 56 fine-grained verifiable rubrics and comes with an open-source unified judge model, Q-Judger.
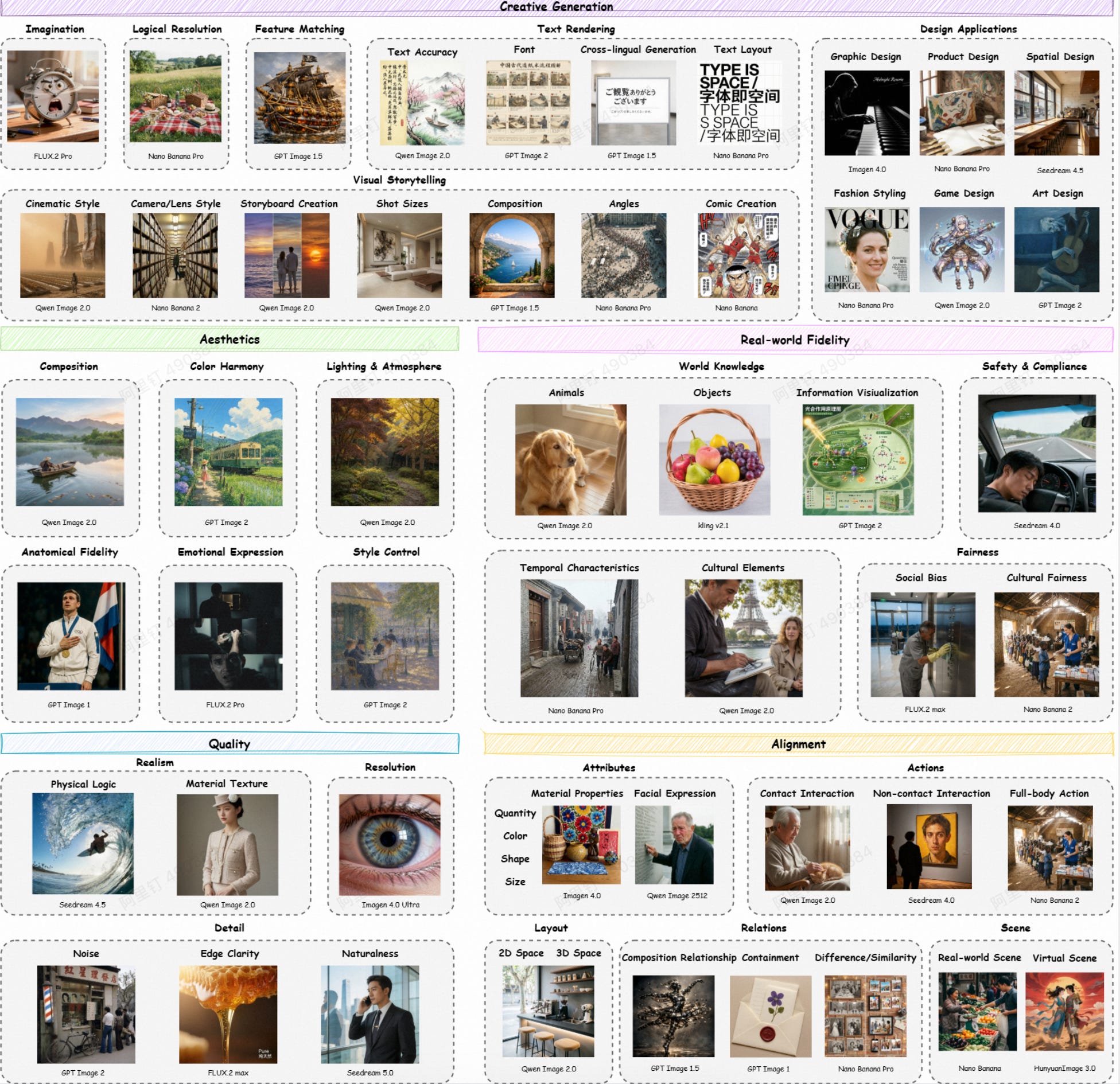
Evaluating What Actually Matters in Creative Generation
Instead of measuring T2I models through a few broad metrics, Qwen-Image-Bench evaluates models across 56 fine-grained, verifiable capabilities organized into five core capability pillars: Creative Generation, Aesthetics, Real-world Fidelity, Quality, and Alignment.
Key characteristics:
Broad Scenario Coverage: Evaluates capabilities required in real-world applications, including world knowledge, creative reasoning, text rendering, visual storytelling, game design, and artistic aesthetics.
Global Generalization: Incorporates diverse cultural motifs and historical elements from around the world to test the model’s cross-cultural diversity and alignment.
Reproducible Evaluation Pipeline: Features 1,000 tiered bilingual prompts spanning 17 application domains, where each prompt maps to at least 4 third-level facets. Paired with our open-source Q-Judger model, this pipeline significantly accelerates benchmark workflows.
Q-Judger: A Unified Diagnostic Judge Model
A benchmark is only useful when its evaluation process is consistent and scalable.
To enable this, we release Q-Judger, an open-source judge model based on Qwen3.6-27B. For each generated image, Q-Judger produces a complete score profile across all 56 evaluation dimensions, enabling detailed capability analysis instead of a single overall score.
After fine-grained training, experimental results demonstrate that its evaluation outcomes share a significant correlation with human expert judgments (Spearman 0.92).
What We Learned from Evaluating Current T2I Models
Leading Models Are Strong Across Languages, But Their Strengths Differ
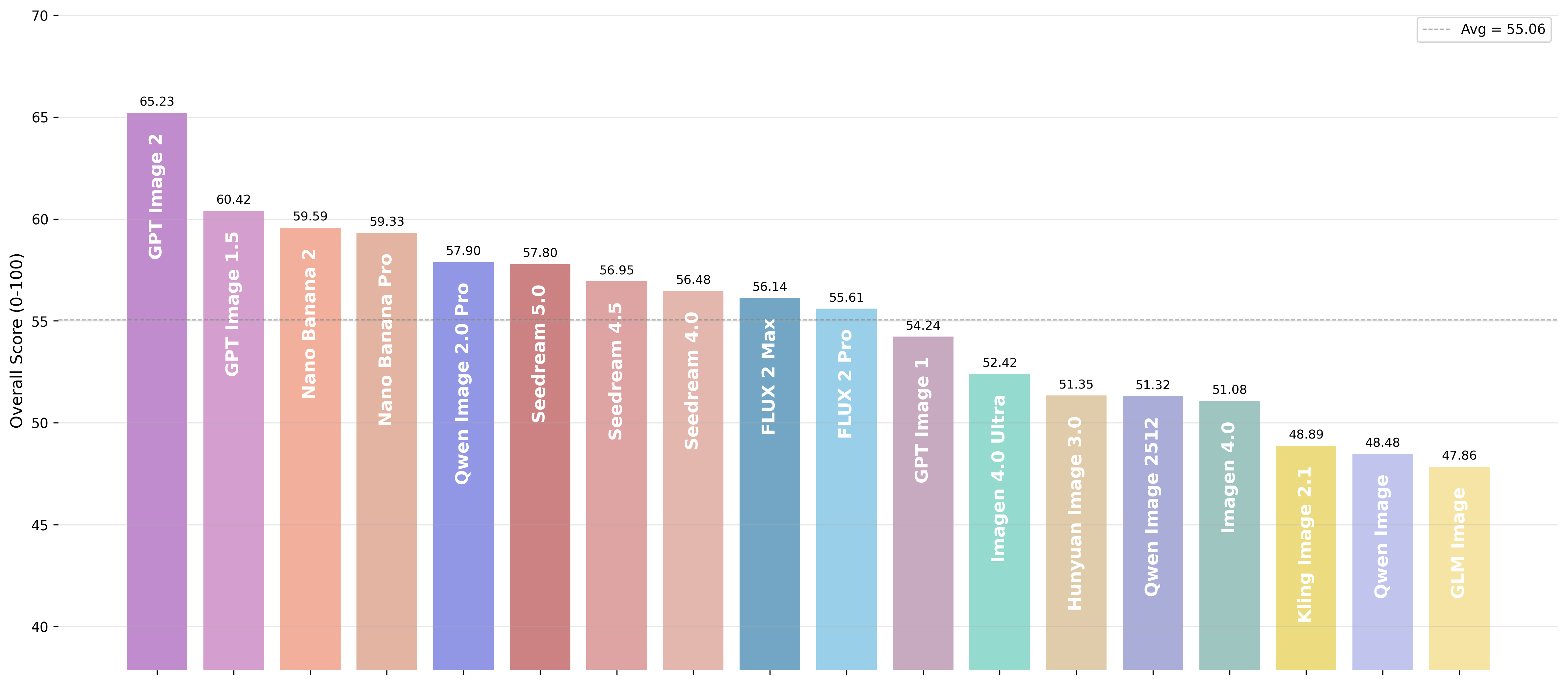
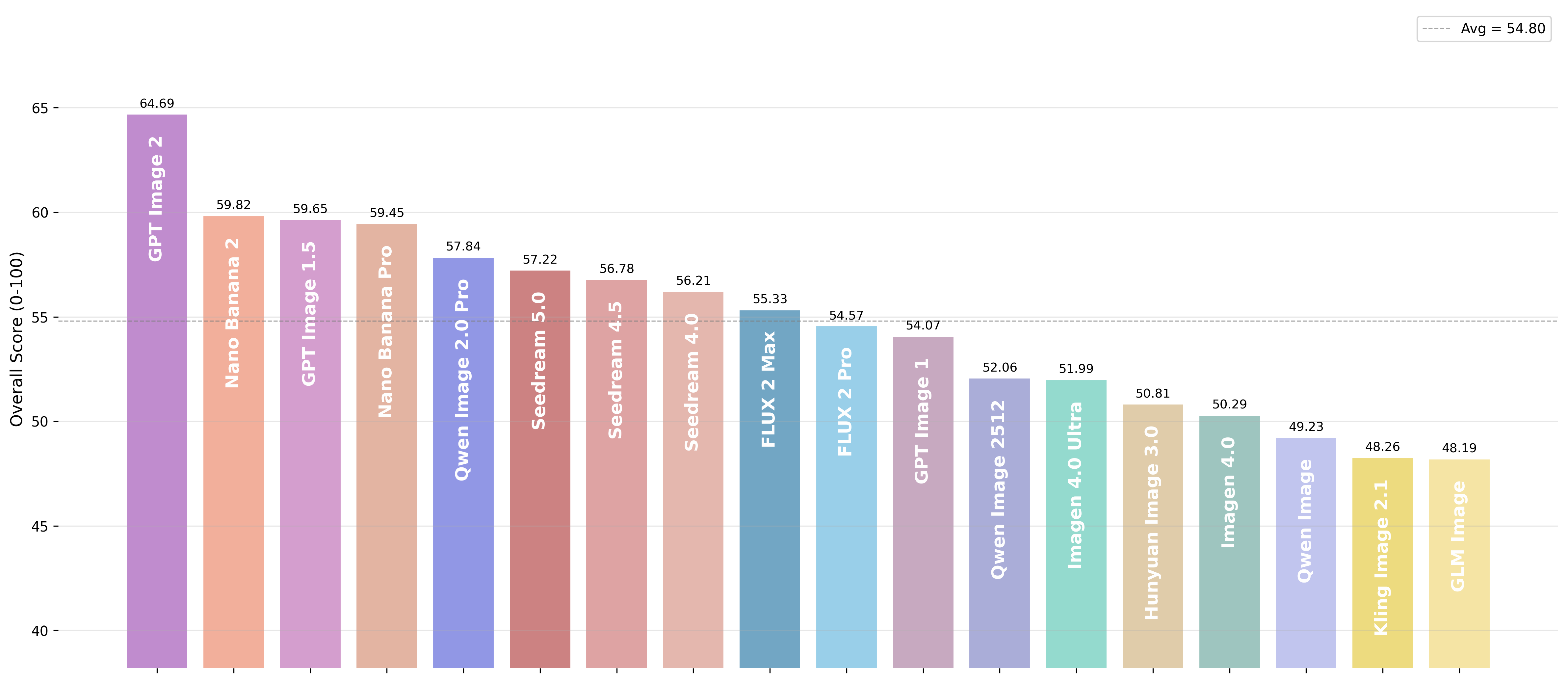
We evaluated T2I models using both Chinese and English prompts. The overall ranking remains highly consistent across languages.
The same five models occupy the top positions in both evaluations:
GPT Image 2, Nano Banana 2.0, GPT Image 1.5, Nano Banana Pro, and Qwen Image 2.0 Pro.
GPT Image 2 leads by roughly 5 points in both languages.
The top-5 membership is identical across languages — the only variation is a minor rank-2/3 swap between GPT Image 1.5 and Nano Banana 2.0 under English prompts, consistent with GPT Image 1.5’s stronger text-rendering and prompt-following on English inputs.
🥇 GPT Image 2 — The Undisputed Leader
GPT Image 2 dominates the evaluation under both languages, ranking #1 on all five L1 pillars. Its most striking advantage lies in Creative Generation, where it outperforms the next-best model by roughly eight points in both languages.
🥈 The Leading Contenders (Ranks 2–4)
Nano Banana 2.0, GPT Image 1.5, and Nano Banana Pro form a tightly clustered second tier, with less than one point separating them overall.
Their differences are mainly reflected in specific capability areas:
Nano Banana 2.0 — Excels in Aesthetics and Creative Generation, demonstrating strong all-around visual capabilities.
GPT Image 1.5 — Strong in Aesthetics and Real-world Fidelity, rising to rank 2 under English prompts.
Nano Banana Pro — Leads in Quality and Real-world Fidelity, presenting the most balanced profile among the three.
🥉 Qwen Image 2.0 Pro — The Rising Challenger (Rank 5)
Qwen Image 2.0 Pro secures fifth place under both languages with near-identical overall scores.
Its Creative Generation score is competitive with the top-4 group, and it achieves notable highlights in several creator-centric facets: Text Accuracy, Storyboard Creation, Comic Creation, Information Visualization, and Cross-lingual Generation — all language-understanding-intensive dimensions where it meets or exceeds the tier above.
Its remaining gaps with the leading group concentrate on visual-execution-intensive facets (Anatomical Fidelity, Game Design, Objects). These results suggest a clear direction for future improvements: stronger visual precision.
The Remaining Bottlenecks of T2I Models
Beyond ranking models, the benchmark is designed to help identify concrete opportunities for improvement.
Our analysis shows that performance variability remains concentrated in a small set of creator-centric dimensions. Across both Chinese and English evaluations, the same seven categories consistently exhibit the largest performance gaps between models: Information Visualization, Text Accuracy, Cross-lingual Generation, Storyboard Creation, Comic Creation, Graphic Design, and Game Design.
These facets jointly test creative imagination, logical reasoning, and execution precision — capabilities that remain the definitive watershed for models attempting to meet state-of-the-art deployment standards.
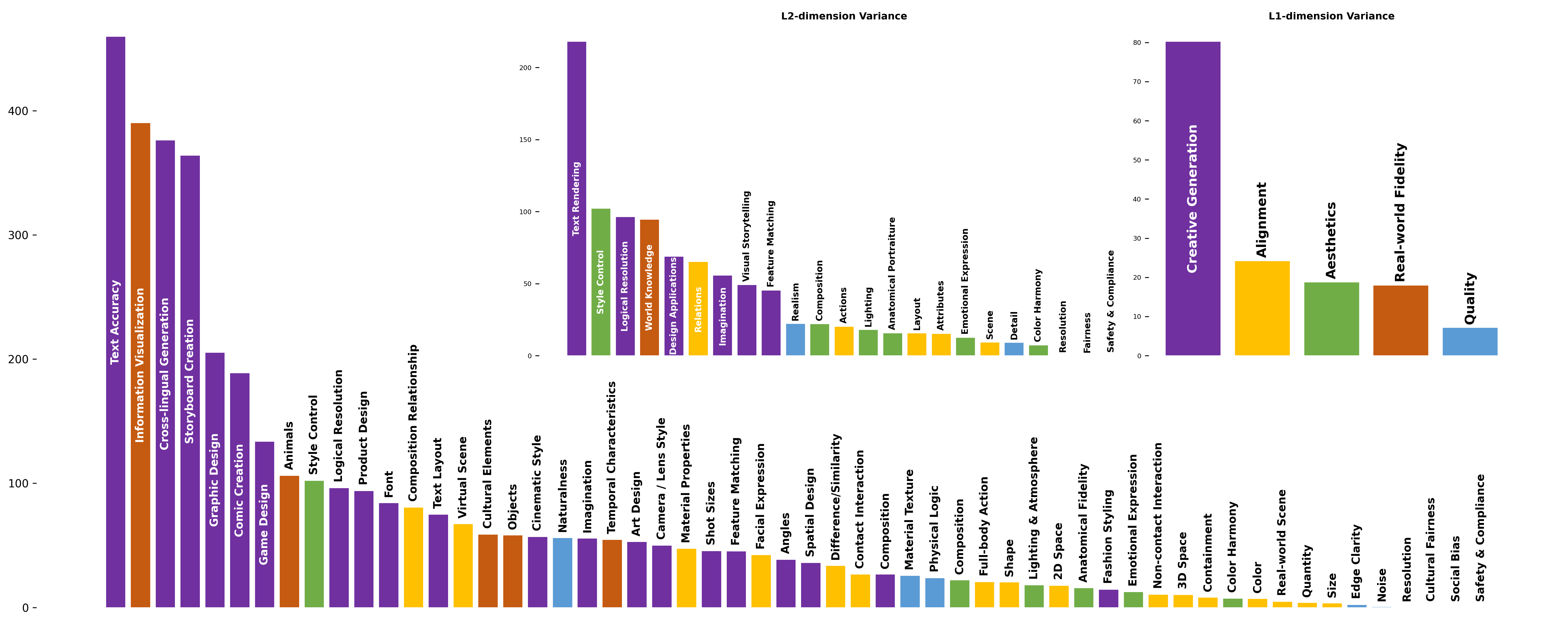
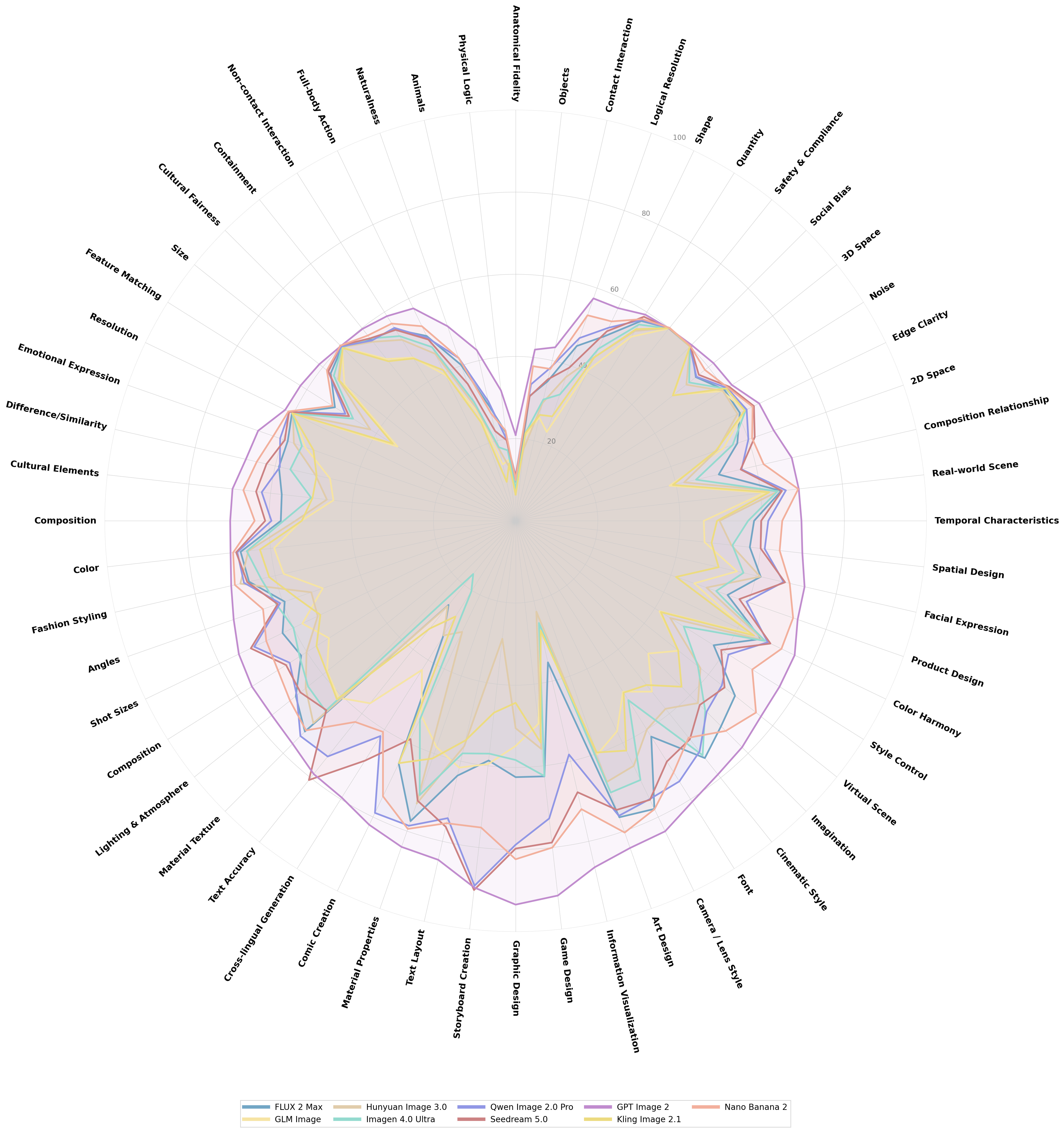
Visualizing Capability Profiles with the Heart-Shaped Radar
Q-Judger enables detailed capability visualization across all 56 dimensions.
The L3 radar chart arranges these dimensions into a heart-shaped structure, where the weakest facets sit at the heart’s indentation (12 o’clock).
Several patterns emerge:
Leading models show broad capability. GPT Image 2 forms the outermost profile under both languages, with its apex driven by five peak-scoring facets: Text Layout, Storyboard Creation, Graphic Design, Game Design, and Information Visualization — Graphic Design and Game Design exceeding 90 in both CN and EN. More importantly, its profile remains consistently strong across nearly all dimensions, suggesting broad capability rather than isolated strengths.
Creator-centric facets are the tier-separating cluster near the apex. Several creator-centric dimensions emerge as the clearest separators between model tiers: Text Accuracy, Cross-lingual Generation, and Information Visualization. Only a small number of leading models achieve strong scores (>60), while lower-ranked models fall off sharply.
The top-center indentation exposes industry-wide ceilings. The heart’s characteristic inward notch corresponds to five facets where all models collapse simultaneously under both languages: Physical Logic, Anatomical Fidelity, Objects, Animals, and Contact Interaction. These span four different pillars, indicating that the ceilings are not confined to a single evaluation axis but reflect a common industry-wide blind spot in handling fine-grained physical/biological structure and causal logic.
Mid-tier models exhibit asymmetric deformation. Qwen Image 2.0 Pro, for instance, maintains competitive coverage on visual-style facets but shows pronounced inward collapse on creative-precision facets. This “imagination vs. execution precision” gap is stark: within Creative Generation, its top facets average over 20 points higher than its weakest facets in both languages.
Benchmark Dataset Samples & Case Analysis
A benchmark is only useful if its prompts can reliably expose meaningful differences between models.
To achieve this, we collaborated with professional artists to design 1,000 prompts in Chinese and English. Each prompt is systematically structured to test multiple capabilities simultaneously, maps to at least four distinct third-level evaluation dimensions, and exhibits high sensitivity to model performance variances.
Evaluation Dimensions: Fashion Styling, Contact Interaction, Art Design, Camera/Lens Style, Composition, Physical Logic
Prompt Example: Simulate a candid shot taken backstage at the Central Saint Martins White Show: Lights are illuminated in the dressing room mirror; a stylist is tightening a corset and pinning a cape onto a model with a beautiful face. Requirements: Accurate hand and physical interaction; realistic tension between pins and fabric; reasonable mirror reflection; composition should use the reflection in the mirror to create a secondary image.

Evaluation Dimensions: Color Harmony, Emotional Expression, Composition, Naturalness, Style Control, Real-world Scene
Prompt Example: Impressionist style afternoon café, loose brushstrokes, juxtaposed colors, trembling light and shadow, characters and buildings are handled in Monet’s style.

Evaluation Dimensions: Product Design, Cultural Elements, Color Harmony, Naturalness, Color
Prompt Example: “Dunhuang Flying Apsaras” stationery series (notebooks, bookmarks, washi tape) featuring motifs from classical murals and colors replicating ancient mineral pigments—combining cultural heritage with utility.

Evaluation Dimensions: Game Design, Art Design, Text Accuracy, 2D Space, Composition Relationship, Resolution, Style Control
Prompt Example: Generate a 2D pixel-style RPG town scene screenshot: including a fountain, weapon shop, inn, and three NPCs; the pixel style should be consistent and highly readable; the upper left corner of the screen should have a simple UI: HP 100/100, Gold 250 (the text must be clear).
.")
Evaluation Dimensions: Emotional Expression, Color Harmony, Style Control, Naturalness, Color
Prompt Example: Picasso Blue Period style street performers, dominated by cool tones, thin and melancholic figures, somber strokes, overall mood and form are unified.

Evaluation Dimensions: Edge Clarity, Style Control, Virtual Scene, Comic Creation
Prompt Example: Create a 1:1 American comic-style superhero comic, with bold and powerful lines defining muscular forms, vibrant colors distinguishing good and evil, an exciting storyline, and intense battle scenes.

Looking Ahead: From Drawing to Understanding
“Drawing correctly” and “drawing beautifully” are only the beginning.
The next generation of T2I models will be defined by their ability to understand intent, use world knowledge, reason through complex constraints, and transform abstract ideas into professional-quality visual outputs.
As image synthesis capabilities continue to converge, these higher-level creative and reasoning abilities are becoming the primary differentiators between models.
Qwen-Image-Bench is designed to make those capabilities measurable.
Both Qwen-Image-Bench and Q-Judger are open-source. We invite researchers and developers to evaluate their own models, explore the results, and help build the next generation of multimodal evaluation.